Plurality voting is terrible and should be replaced, but what's the best voting system to replace it with? This isn't a new revelation, or a new question; for instance Thomas Jefferson considered the problem. But academic inquiries to it had been in a lull since Kenneth Arrow's Nobel-prize-winning work in 1950 showed that, given certain assumptions, there was no perfect system. Social-decision scientists everywhere were crushed.
What little debate that continued about the subject focused around various "voting system criteria". Arrow's work had shown that a group of five certain "clearly necessary" criteria were mutually exclusive, but perhaps by breaking certain ones in a minimally-damaging way an almost-perfect voting system could be found. The problem was, no one could agree which criteria were most important; each practitioner could always come up with some worst-case scenario in which their opponents latest new proposal clearly gave a horrible result (usually involving a candidate named "Hitler" winning the election, just to make the point clear.) And so the debate degenerated to what situations were more likely to come up or led to more damaging results: the terrible one I concocted for your new voting system, or the terrible one you concocted for mine. But all these arguments lacked one important piece: evidence.
To make good estimates of how often various worst-case scenarios happen and how bad they are, it would take at least hundreds of elections, each with a minimum of a few hundred participants, multiplied by each of dozens of systems that had been developed, in order to get a clear picture. But even then, what do you measure? When your experiment is to ask people "what's the best ice-cream favor," how do you measure whether the voting system was right without knowing the right answer ahead of time? And how would you determine the right answer ahead of time, without asking people to vote on it?
The problem is that economic utility can't be measured directly. Combined with the in-feasibility of performing enough test-elections, it's enough to make almost anyone throw up their hands in frustration.
But here's a clever idea: what if we replace real people with little bits of computer code? Instead of futilely trying to measure each participants utility, we can just assign them randomly from a statistical distribution. We'll have each little bit of code "vote" using every one of the electoral methods we've developed, but also calculate what the maximum possible utility could be from each election, and see how much we miss by. And we'll do it a few hundred times and take the average. Running the whole simulation should take maybe a long weekend. (If only Arrow had had access to a modern desktop computer!) What would we find? Let's ask Professor Warren D. Smith, who ran this simulation over the 1999/2000 New Year's holiday.
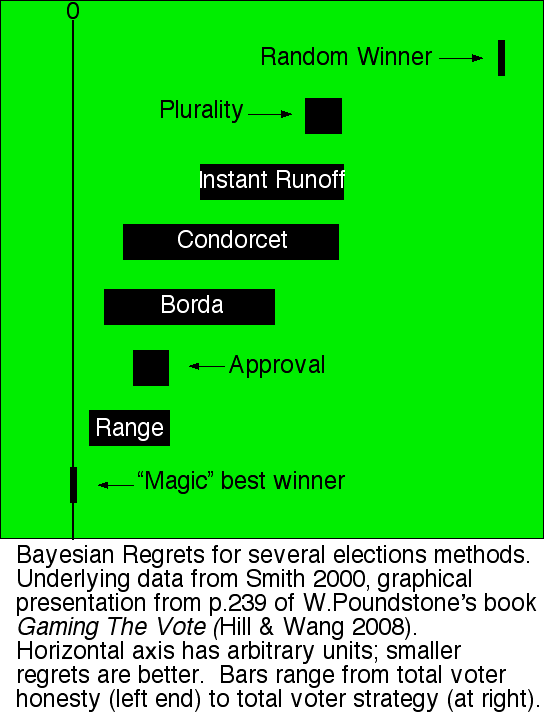
If the data from this simulation is to be believed, using approval voting, or score voting (listed here as range voting), could improve the results of our elections by the same proportion as voting at all is an improvement over choosing our leaders at random. That's an astounding result!
Of course, there are still critics: most of them just repeat their favorite criteria argument (usually later-no-harm or majority, since score and approval fail them) ignoring that this data already accounts for any downsides from those short-comings. A few smug folks point out that you can't measure utility; but we already know that, that's why we used a simulation. Some attacked the statistical distribution of utility (now we're getting to something meaty!), so a series of better distributions, based on their suggestions, were used: the results were virtually the same. Then they argued that voters are a poor judge of their own utility; so the experiment was rerun with a "voter uncertainty" parameter. Even with a 50% error factor, score and approval still top the list.
The most bizarre argument is that score and approval can't be the best voting systems, because they aren't voting systems at all. You see, one of Arrow's assumptions was that a voting system would convert a set of all voter's "ranked-order preferences" into a societal order of ranked preferences. But score and approval don't used ranked-order preferences; perhaps, if Arrow hadn't used this overly-restrictive requirement, it wouldn't have taken 50 years to find these results.
Not only is this an astounding result, it seems to be a fairly unassailable result. The "best" voting system is score voting, and approval is almost as good (but easier to implement).
I think the argument RE: LNH was that it wasn't accounted for properly during Warren's simulation because he didn't attempt to simulate voter psychology that leads to bullet voting in Score, Approval, and Bucklin, and truncation in all rank systems that allow it.
ReplyDeleteI believe it would be easy to implement, possibly as an added effect to the ignorance factor.
Aside from that, you're completely right about score being the best by far, with approval also quite good.
And, Arrow couldn't have specified a set larger than rank order systems, because then the impossibility theorem wouldn't work. The rank order is the reason the systems fail.
@AnOctopus
ReplyDeleteThere is absolutely no evidence that voter psychology leads to a significant amount of "bullet voting". For instance, imagine those Nader supporters back in the 2000 election who strategically voted for Gore were allowed to vote for as many candidates as they wanted. Obviously they would have voted for Nader in addition to Gore. The opportunity to vote for more than one candidate obviously wouldn't make them want to switch their vote from Gore to Nader.
http://www.electology.org/debate/BulletVoting
This is a good post, and an argument that warrants repeating. I think it would have been a good addition to mention Arrow's look at range voting (see pg 254 Gaming the vote) and how he improperly dismissed it.
ReplyDeleteI plan to eventually do some posts looking at range compared to other systems in an easy to understand way. The more we have speaking out on this extremely important issue the merrier. That goes double for Warren's Bayesian Regret. Keep it up.
@broken ladder
ReplyDeleteFirst, I'm not one of the ones who believe that bullet voting is all that common in SV; I was just repeating the most reasonable unaddressed argument I've heard.
It would also seem to only apply in nonpartisan elections.
I'd like to see how using a first 6 or 7 past the post (based on signature gathering) to pick the candidates in the primary, and then an AV (where you have to pick 3 different candidates) to pick the top 3 and then IRV to pick the last one wd fair under this sort of test.
ReplyDeleteI believe Arrow's impossibility theorem implication is that one election does not fit all and that whether an election "works" is ultimately a matter of experience and something that shd be open for experimentation.
dlw
@DLW,
ReplyDeleteI don't know that Arrow's Theorem has the implication you describe. But here it is verbatim.
http://scorevoting.net/ArrowThm.html
...and IRV still often picks the wrong winner, even when there are only three options to choose from.
ReplyDeletedefine "often" picks the wrong winner...
ReplyDeleteOne can find theoretical eg where it wd be pick a wrong winner, but as to how often such would occur when there's only 3 candidates, that's to be determined...
It also depends on how well rationally irrational low-info voters follow the ideal of Approval or Score Voting in practice. You're graph presumes a homogenous use of best practice and in real life that just ain't necessarily so...
dlw
It has been determined, by simulation. And the graph doesn't assume best practice (read the note about %honesty.)
ReplyDeleteThe first hint is in the BR scores. Since BR is defined as the difference between maximum utility outcome and expected outcome for each voting system (or, alternatively/equivalently, the difference between minimal regret and expected regret), the fact that IRV has worse BR scores implies that it either picks the wrong winner more often, or, when it does pick a wrong winner, it picks a "wronger" one; or some combination of the two.
But there's a more precise way, since Smith provides this exact data: how often do the IRV winner and the best (highest utility) winner agree?
And with 3 candidates, it's about 70% of the time; i.e., the "wrong winner" is chosen about 30% of the time.
Approval though, get's it right 74% of the time.
For comparison: plurality gets it right 66% of the time, and score gets it right 78% of the time.
This is all using the "random normal election model" with 100% honest voters, but as before, with other models and other degrees of honesty, the relative performance of different methods doesn't change that drastically. And often, even if you assume approval or score voters are evil devious tacticians, while IRV voters are paragons of self-sacrificing virtue, approval and score STILL WIN. So your concerns about it being "different in the real world" cannot possibly swing the data in your favor, because even when given the largest-possible benefit of the doubt to your concerns, at best it comes out as a wash.
Source: http://rangevoting.org/RandElect.html
@dlw
ReplyDeletedefine "often" picks the wrong winner...One can find theoretical eg where it wd be pick a wrong winner, but as to how often such would occur when there's only 3 candidates, that's to be determined...
As shown here, with 3 candidates IRV picks the wrong winner about 29% of the time.
But that's not telling the full story, since some wrong winners are worse than others. For instance, I could deduct 1000 dollars from your salary every 5th month, or deduct 25 dollars every month; while the second scenario means you get the wrong salary more often, it's preferable to the first scenario because when it's wrong, it's off by a much smaller amount.
When you multiply frequency of wrongness by severity of wrongness, you get Bayesian regret.
It also depends on how well rationally irrational low-info voters follow the ideal of Approval or Score Voting in practice. You're graph presumes a homogenous use of best practice and in real life that just ain't necessarily so...
The properties of the voters are statistically the same for every election method, so there's no favoritism going on for Score or Approval Voting in the graph.
As far as homogeneousness is concerned, it has been shown that Score and Approval Voting still dominate when one segment of the electorate is more tactical than the other (i.e. when tactical behavior is not homogenous).
http://scorevoting.net/StratHonMix.html
With this method of voting, won't you still end up with a bunch of small minded well intentioned idiotic tyrants ruling everyone else by force?
ReplyDelete